
The landscape of AI language models has been dominated by proprietary systems requiring massive computational resources. However, a new contender, S1, is redefining what’s possible with efficient training techniques and open-source transparency. Developed by researchers from Stanford University, the University of Washington, and the Allen Institute for AI, S1 showcases a novel approach to improving reasoning capabilities without exponential increases in computational cost.
It seems the next breakthrough will come to the optimization of the reasoning methodologies.
I envision two different engineering paths we should follow to better inferencing LLM models:
- prompt engineering
- reasoning engineering (I wrote a post about this).
Technical Overview
S1 employs a test-time scaling approach, allowing the model to enhance its reasoning capabilities dynamically during inference rather than solely relying on pre-training. At its core, S1 is built upon Qwen2.5-32B, a pre-trained large language model, and fine-tuned using a carefully curated dataset, s1K, consisting of 1,000 high-quality reasoning problems.
The most significant innovation introduced by S1 is budget forcing, a mechanism that regulates the number of tokens a model uses for reasoning. This technique ensures that the model spends a controlled amount of computational effort by either terminating early when the response is deemed satisfactory or appending additional tokens (e.g., “Wait”) to encourage further reasoning. By optimizing how long a model “thinks,” budget forcing improves accuracy while keeping computational costs predictable.
In depth analysis
The development of S1 focused on creating a highly efficient model that leverages test-time scaling to optimize reasoning without excessive training costs. The researchers began by curating an extensive dataset of 59,029 reasoning-focused questions from diverse sources, covering subjects like mathematics, physics, computer science, and economics. This dataset was then filtered down to a high-quality subset of 1,000 examples (s1K) based on criteria such as problem difficulty, diversity, and overall reasoning quality.
To fine-tune the model, the team selected Qwen2.5-32B-Instruct and applied supervised fine-tuning (SFT) using the s1K dataset. The training process lasted 26 minutes on 16 NVIDIA H100 GPUs, making it highly cost-effective. This approach allowed the researchers to avoid the costs associated with training a model from scratch while achieving significant performance improvements.
A crucial innovation of S1 is budget forcing, ensuring controlled inference-time computation. This technique enforces a maximum token threshold (e.g., 32,000 tokens) or encourages extended reasoning through additional prompt engineering. By guiding the model’s reasoning process, budget forcing improves accuracy while maintaining computational efficiency.

Performance and Scaling Analysis
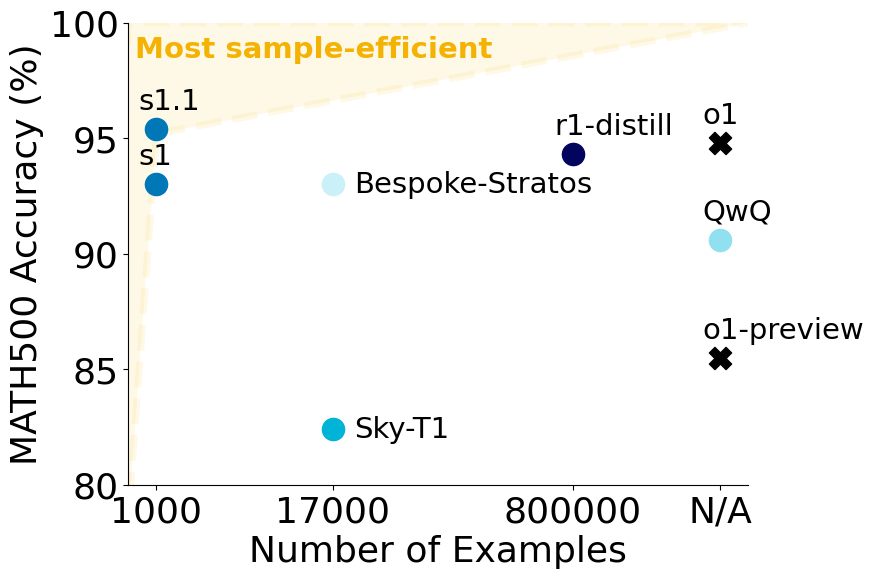
Empirical evaluations demonstrated that S1 is the most sample-efficient reasoning model in its category. The model achieved 93.0% accuracy on MATH500, 56.7% on AIME24, and 59.6% on GPQA Diamond, outperforming OpenAI’s o1-preview model on several key benchmarks.
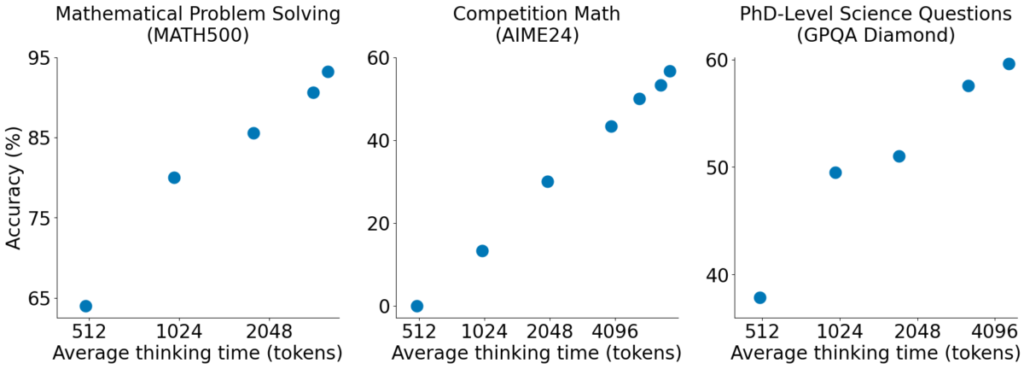
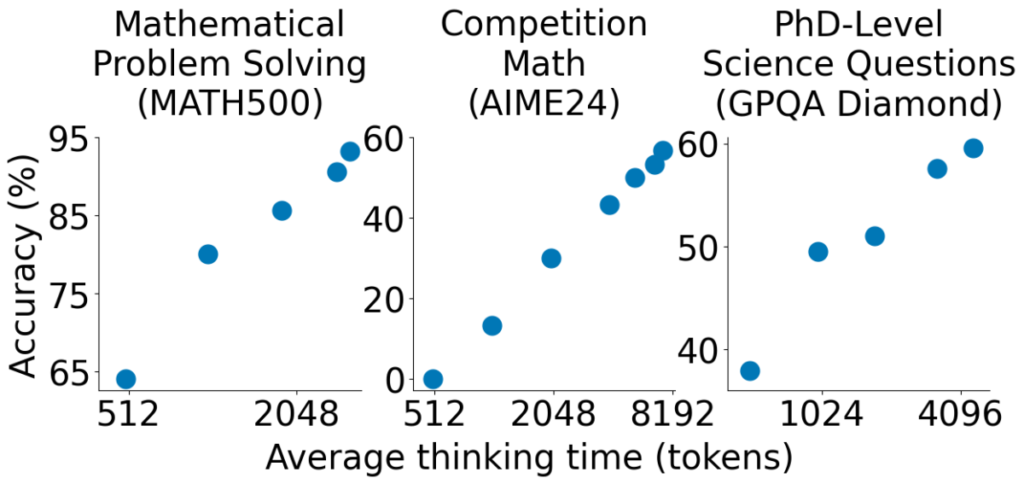
An analysis of scaling accuracy with token usage across different benchmarks reveals valuable insights:
- Accuracy improves with increased thinking time across all benchmarks. This suggests that models benefit from additional reasoning time.
- MATH500 achieves the highest accuracy, reaching above 90% when the model is allowed to process more tokens.
- AIME24 starts with very low accuracy, close to 0% at 512 tokens, but improves significantly as thinking time increases.
- GPQA Diamond shows a steady improvement, with accuracy rising from around 40% to 60% as token usage increases.
These results reinforce the importance of allowing sufficient token processing for complex reasoning.
Different benchmarks show different scaling behaviours, suggesting that the optimal thinking time varies by task complexity.
The findings support the concept of budget forcing in AI models, as controlling token usage impacts both accuracy and computational cost.
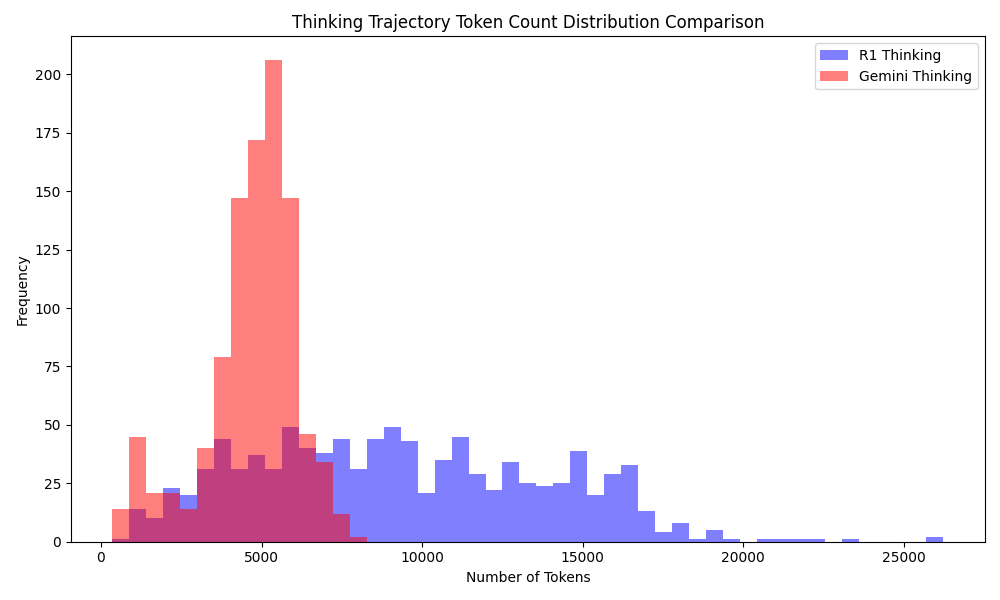
Training Efficiency: is $50 Enough?
A key claim around S1 is that it was trained for only $50. However, this statement requires clarification. The actual training involved fine-tuning an existing model (Qwen2.5-32B) rather than building S1 from scratch. The fine-tuning process lasted 26 minutes on 16 NVIDIA H100 GPUs, making the cost calculation realistic for that specific training session.
However, if one were to consider the cost of training the base model, the total expenses would be significantly higher.
S1’s success highlights the power of test-time scaling and budget forcing in improving reasoning efficiency. Future work could explore expanding the dataset beyond mathematical problems to cover a broader range of domains or integrating reinforcement learning techniques to further optimize its decision-making process.
By offering an open and efficient alternative to closed-source models, S1 sets a precedent for democratizing AI development. The project’s repository, available on GitHub and Hugging Face, invites contributions from the broader AI community, fostering innovation in efficient language modeling.
- Link: https://arxiv.org/pdf/2501.19393
- Download the model: https://huggingface.co/simplescaling/s1.1-32B
- Open source code: https://github.com/simplescaling/s1
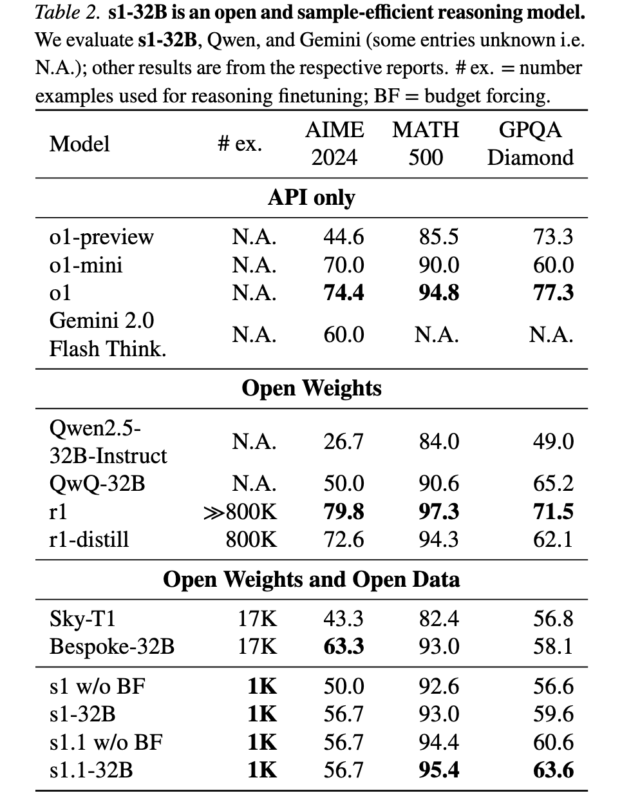
Pros and Cons of S1
Pros:
-
Highly Efficient Reasoning: S1 achieves strong performance using a minimal dataset (1,000 examples), showcasing remarkable efficiency compared to models requiring hundreds of thousands of samples.
-
Open-Source Transparency: Unlike proprietary models, S1’s code, dataset, and model weights are publicly available, allowing researchers and developers to build upon it.
-
Controlled Computational Cost: Budget forcing ensures that the model’s test-time reasoning remains predictable, avoiding uncontrolled spikes in inference costs.
-
Competitive with Proprietary Models: S1 demonstrates reasoning capabilities similar to OpenAI’s o1-preview while using significantly fewer resources.

Cons:
-
Not Trained from Scratch: The claim of training a state-of-the-art model for $50 is misleading—S1 is fine-tuned from Qwen2.5-32B rather than developed independently.
-
Limited by Pretrained Knowledge: Since S1 is based on an existing model, its capabilities are constrained by the knowledge embedded in Qwen2.5-32B.
-
Potential for Overfitting to Reasoning Tasks: While S1 excels at structured problem-solving, its effectiveness on more diverse NLP tasks remains uncertain.